原理
通过相邻元素比较交换的方式,将最大的元素依次移动到列表中未排好序部分的尾部,重复操作,直到列表中未排好序的部分为空,从而使整个列表有序
scala实现思路
通过相邻元素比较交换的方式,将最大的元素依次移动到列表中未排好序部分的尾部,重复操作,直到列表中未排好序的部分为空,从而使整个列表有序
- 新建一冒泡函数bubble(unSorteds: List[A]): A,实现一趟冒泡功能,即从输入列表中冒泡出一个最大元素A
- 给bubble函数添加两个参数remains: List[A], accOrdereds: List[A],添加后函数如下:bubble(unSorteds: List[A],remains: List[A], accOrdereds: List[A]): A
其中remains用于记录每次冒泡后去掉冒出去的元素后剩余元素列表,
accOrdereds用于累积每趟冒泡冒出来的元素,然后将返回值A改为List[A],即返回累积排好序的列表。
函数bubble使用“模式匹配”匹配为排序的列表,分两种情况 - 列表中至少有两种元素的情况
- 列表中只剩余一个元素
这种情况下,当剩余元素列表remains为空时,说明整个排序完成。否则继续递归bubble
具体实现
循环
1 | /** 冒泡排序 时间复杂度 n2 */ |
尾递归
1 | /** |
1 | def bubbleSortV3(list: List[Int]): List[Int] = { |
原理
使用分治思想,将数列用选好的基准点划分为两个子序列(也就是将比基准点小的元素放左边,比基准点大的元素放右边),递归对子序列使用此方法进行此操作,递归到最底部时,数列的大小是零或一,也就是已排好序。
实现思路
利用scala的模式匹配对序列进行匹配,分两种情况:
序列为空:为空时返回一个空的List()
序列由head和tail组成,head不为空:
这时候以head为基准点将序列划分为left和right两个子序列,然后然后对left和right进行同样操作并将结果quickSort(left)和quickSort(right)与基准元素head连接起来,如此递归操作,直到所有子序列都为空,便已排好序。
代码
1 | def quickSort(list: List[Int]): List[Int] = list match { |
原理
通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入,直到将所有未排序数据都插入到已排序序列中,排序便完成
scala实现思路
- 新建一个insert函数实现将一个元素插入到已排序序列的功能,函数签名如下 def insert(a: A, accOrdereds: List[A]): List[A],其中accOrdereds为已经排序序列,且是累积的,即每次insert时传入的都是当前最新的已排序序列。此函数实现思路也是使用模式匹配来实现。
这种情况下 - 新建一sort函数,函数签名如下:
def sort(unSorteds: List[A], accOrdereds: List[A]): List[A]
其中unSorteds是以模式匹配的方式匹配头和尾,将头元素使用insert函数插入到累积的已排序的序列。然后再使用sort进行下一轮插入。如此递归执行,直到为排序序列unSorteds为空,返回累积已经排好序的序列
注意
scala中List的头(head)是List中第一个元素,List的尾(tail)是去掉头元素(head)后的List
scala代码实现
尾递归实现
1 | def insertSortV2(list: List[Int]): List[Int] = { |
循环实现
1 | def insertSort(list: List[Int]): List[Int] = list match { |
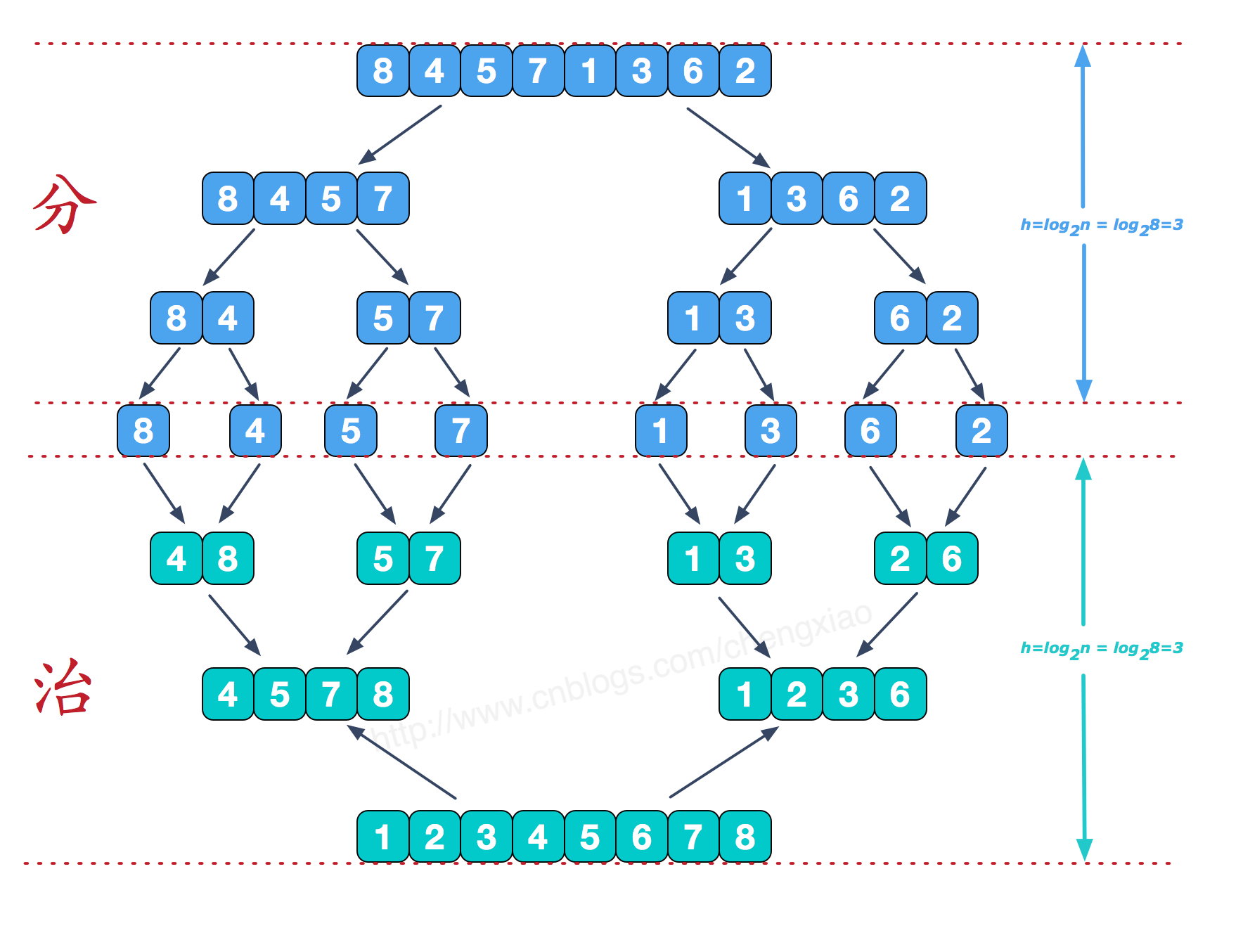
原理
使用分治思想,将序列划分为若干个只有一个元素的子序列,重复进行merge排序操作,将子序列两两合并,直到最后只剩下一个子序列,这个子序列就是已排好的序列
scala实现思路
- 创建一个merge函数用于合并两个排好序的子序列
def merge(as: List[A], bs: List[A]): List[A]
实现方式通过内建一个loop函数,实现对两个序列的遍历和排序,loop函数签名如下:
def loop(cs: List[A], ds: List[A], accSorteds: List[A]): List[A]
cs和ds是两个已排序序列,accSorteds是累积排序序列,cs和ds合并过程中产生的新的有序列序列 - 新建一个划分序列并将划分序列合并排序的函数:
splitIn2AndSort(as: List[A]): List[A]
scala代码实现
1 | def mergeSort(list: List[Int]): List[Int] = { |
思路
从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素,然后放到已排序的序列的末尾。以此类推,直到全部待排序的数据元素的个数为零。选择排序是不稳定的排序方法。
代码
1 | def selectSort(list: List[Int]): List[Int] = { |