题目:青蛙跳台阶
一只青蛙一次可以跳上1级台阶,也可以跳上2级台阶。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。
1 | 示例 1: |
一只青蛙一次可以跳上1级台阶,也可以跳上2级台阶。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。
1 | 示例 1: |
一个ArrayBuffer缓冲包含数组和数组的大小。对数组缓冲的大多数操作,其速度与数组本身无异。因为这些操作直接访问、修改底层数组。另外,数组缓冲可以进行高效的尾插数据。追加操作均摊下来只需常量时间。因此,数组缓冲可以高效的建立一个有大量数据的容器,无论是否总有数据追加到尾部。
1 | scala> val buf = scala.collection.mutable.ArrayBuffer.empty[Int] |
转自「过往记忆微信公众号」。
对 Spark/Hadoop 这样的分布式大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。
对于分布式系统而言,理想情况下,随着系统规模(节点数量)的增加,应用整体耗时线性下降。如果一台机器处理一批大量数据需要120分钟,当机器数量增加到3台时,理想的耗时为120 / 3 = 40分钟。但是,想做到分布式情况下每台机器执行时间是单机时的1 / N,就必须保证每台机器的任务量相等。不幸的是,很多时候,任务的分配是不均匀的,甚至不均匀到大部分任务被分配到个别机器上,其它大部分机器所分配的任务量只占总得的小部分。比如一台机器负责处理 80% 的任务,另外两台机器各处理 10% 的任务。
『不患多而患不均』,这是分布式环境下最大的问题。意味着计算能力不是线性扩展的,而是存在短板效应: 一个 Stage 所耗费的时间,是由最慢的那个 Task 决定。
由于同一个 Stage 内的所有 task 执行相同的计算,在排除不同计算节点计算能力差异的前提下,不同 task 之间耗时的差异主要由该 task 所处理的数据量决定。所以,要想发挥分布式系统并行计算的优势,就必须解决数据倾斜问题。

Error:scalac: Error: org.jetbrains.jps.incremental.scala.remote.ServerException
java.lang.StackOverflowError
IDEA执行Scala程序时,报错:
1 | Error:scalac: Error: org.jetbrains.jps.incremental.scala.remote.ServerException |
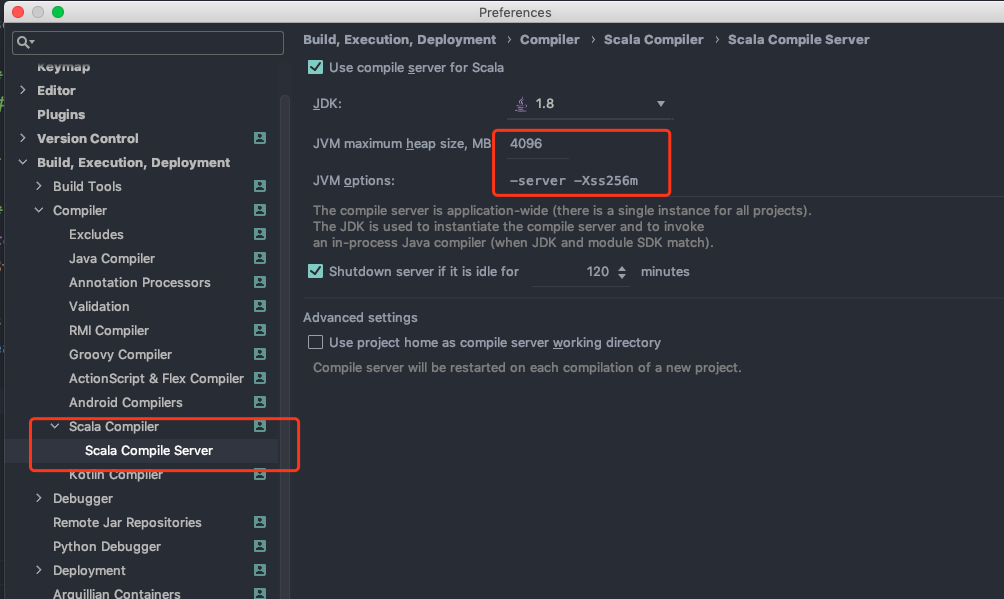
在IDEA关于的Scala的配置中,设置JVM参数。

使用GitHub Actions操作进行Hexo托管在GitHub上面的博客自动化部署。

